什么数组?
数组是一种 线性表 数据结构。它用一组 连续的内存空间,来存储一组 相同类型 的数据。
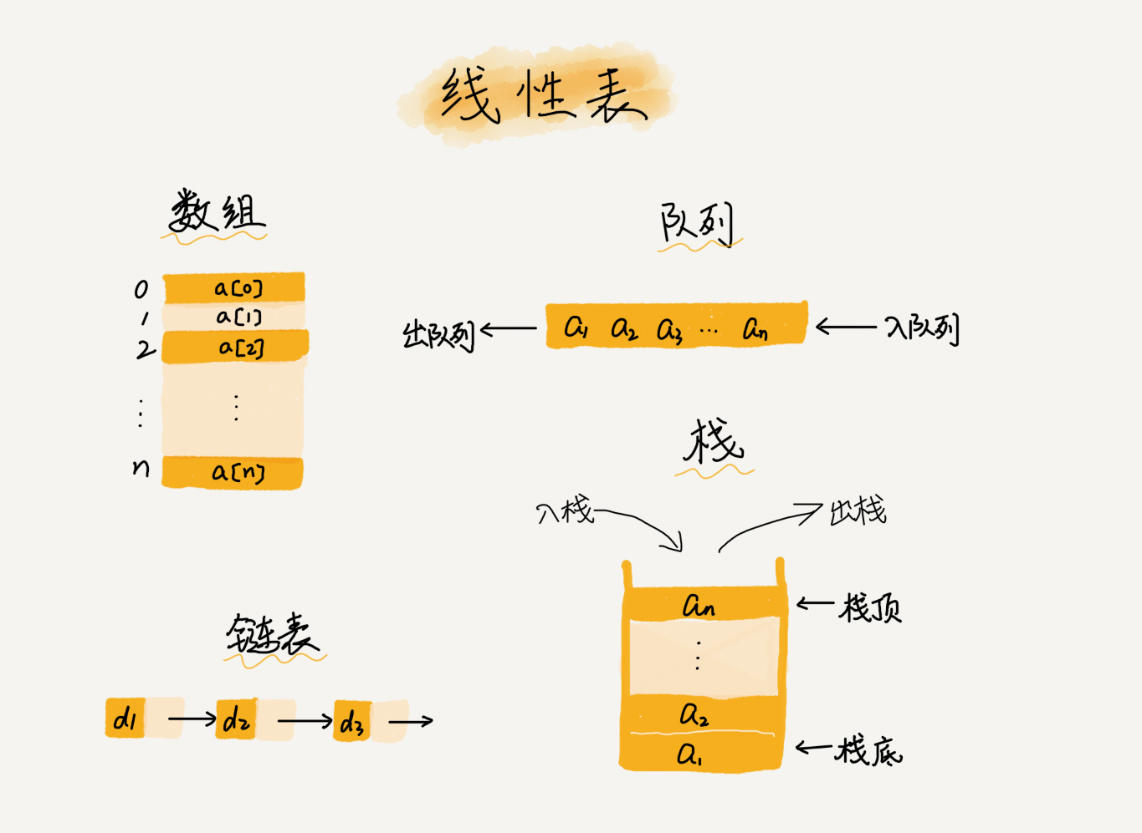
线性表
数据排成一条线一样的数据结构。除了数组,还有链表、队列、栈等都是线性表结构。
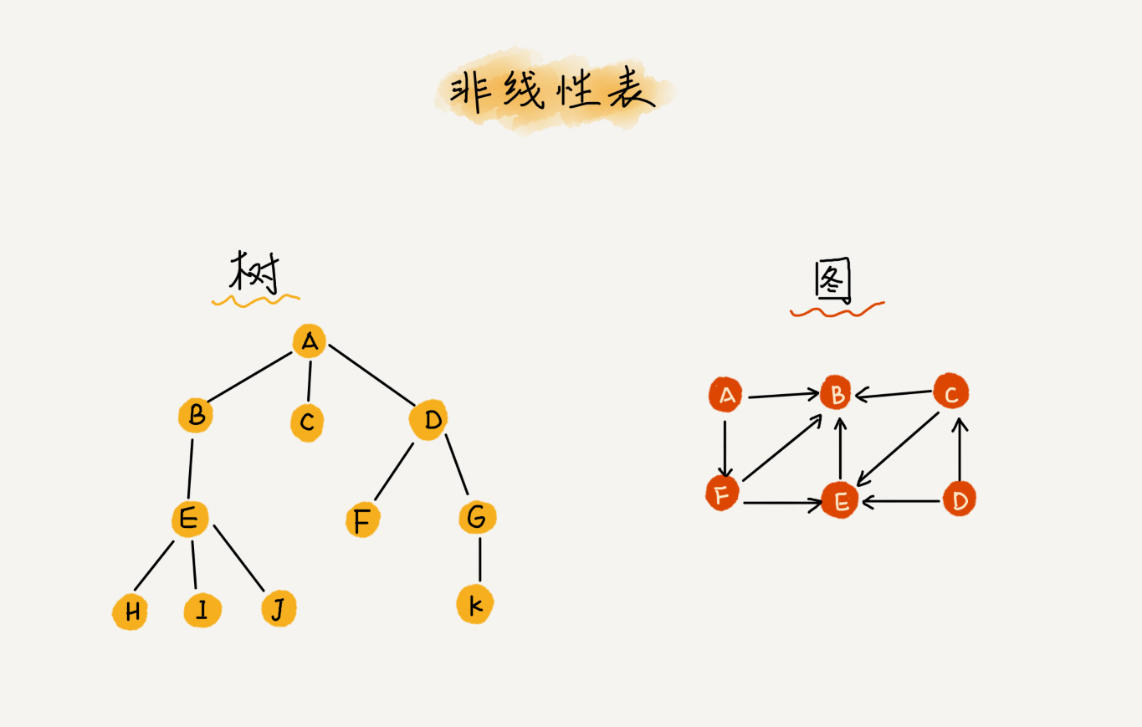
而与之对立的概念称为非线性表,属于这类数据结构的有:树、图、堆等。
连续的内存空间和相同类型
相同类型:很好理解,存储的数据都属于某一种类。
连续的内存空间:
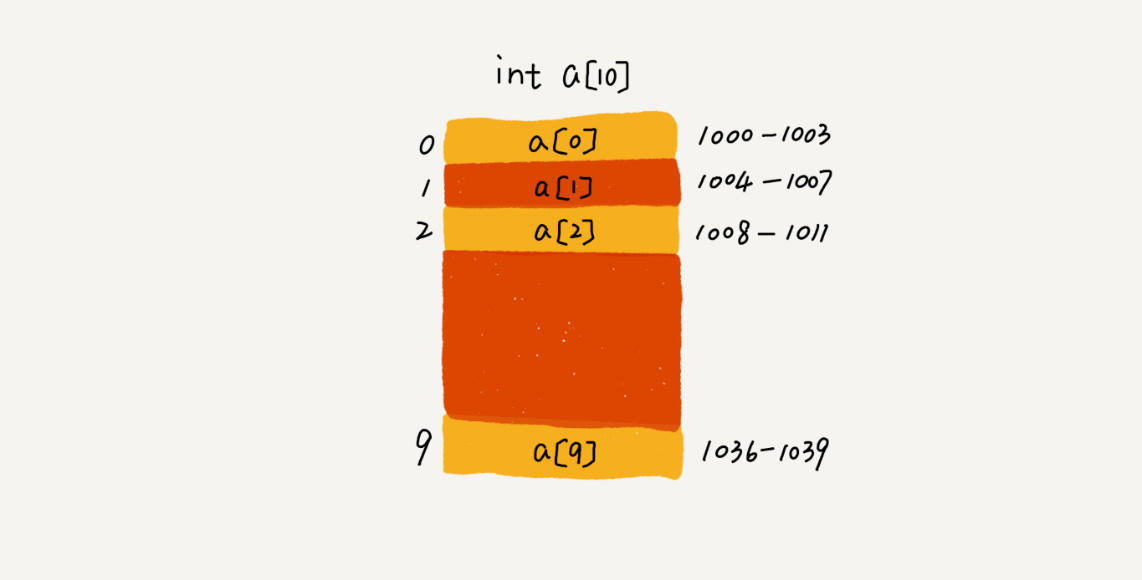
拿上面大小为10整型数组内存图举例,假设分配的内存地址从1000开始,那么第一个元素内存地址就是1000-1003的位置(整型数据占4个字节),总共有10个元素,最后的结束位置就是1039,这就是连续的内存。
高效的查询
试想想,已知数组a的首地址是1000,我们怎么最快的读取到a[1]内存中的数据?
是不是 1000 + 4 = 1004 的内存地址?
a[2]、a[3]呢?
a[2]内存地址 = 1000 + 2 * 4 = 1008
a[3]内存地址 = 1000 + 3 * 4 = 1012
从而我们发现规律,并得出寻址公式:
a[i]_address = base_address + i * data_type_size
有了这个公式我们便能快捷的读写对应的数组元素,这种特性称之为随机访问 。
这里还有一个小知识,数组的下标从0开始是为了更方便的套入到寻址公式中计算,如果从1开始每次寻址时需要多1步减法操作,数组作为最常用的数据结构,多少会有点性能消耗。
有了寻址公式,通过下标查询某元素的时间复杂度为:O(1)
低效删除和插入
为什么会导致低效?又有哪些改进方法呢?
插入操作
假设数组的长度为n,我们想把某个数插入到数组k小标所在位置,那么为了腾出k的位置,我们需要把k-n的所有元素顺序往后移动一位。
试着分析下上面这段操作的时间复杂度:
如果要插入的元素下标为最后1个元素,需要移动元素为:0
插入下标为倒数第1元素,需要移动元素:1
插入下标为倒数第3元素,需要移动元素:2
…
插入小标为第1个元素,需要移动元素:n
插入元素到任意位置的概率是1/n
f(n) = 1+2+3+…+n / n = n/2*(n+1) / n = n(n+1) / 2n
T(n) = O((n+1) / 2) = O(n)
通过以上分析,得出插入有序数组操作的时间复杂度如下:
- 最好情况时间复杂度为:O(1)
- 最坏情况时间复杂度为:O(n)
- 平均情况时间复杂度为:O(n)
有没有别的方法?
如果插入前提需保证数组的数据是有序的,那么就必须按照上面的方法来搬移k之后的元素。
但如果仅是将某个元素插入到指定位置,而不考虑元素中原有的顺序,我们可以先将原k元素放到数组末尾,再将新元素插入到k的位置,如图:
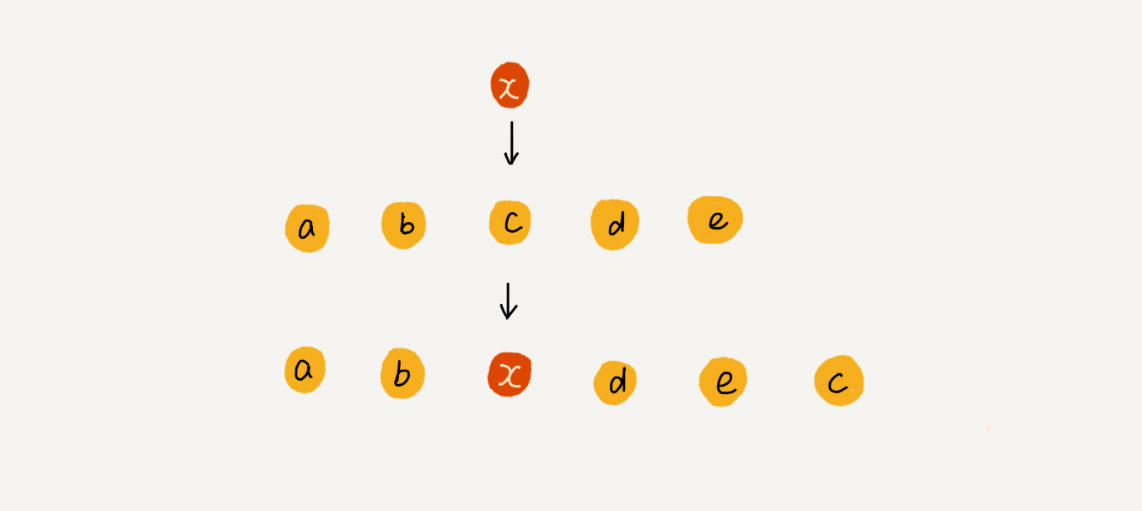
利用上面这种方式,在特定场景中,它的时间复杂度为:O(1)
删除操作
与插入类似,要删除数组中k的元素,就需要把k-n都向前移动1位,从而保证数组的内存连续性,那么删除末尾元素移动为0,删除第1个元素移动为n,所以删除操作的时间复杂度和插入是一样的:
- 最好情况时间复杂度为:O(1)
- 最坏情况时间复杂度为:O(n)
- 平均情况时间复杂度为:O(n)
当然在某些特定的场景下,我们也可以对删除操作进行优化,例如我们有a,b,c,d,e,f,g,h组成的一个数组,我们依次删除a,b,c时,位移操作就要进行3n遍;如果现在的场景并不要求数组中实时的连续性,我们就可以分别将a、b、c先标记成删除状态,当数组没有多余的存储空间时,再做统一的实际删除。
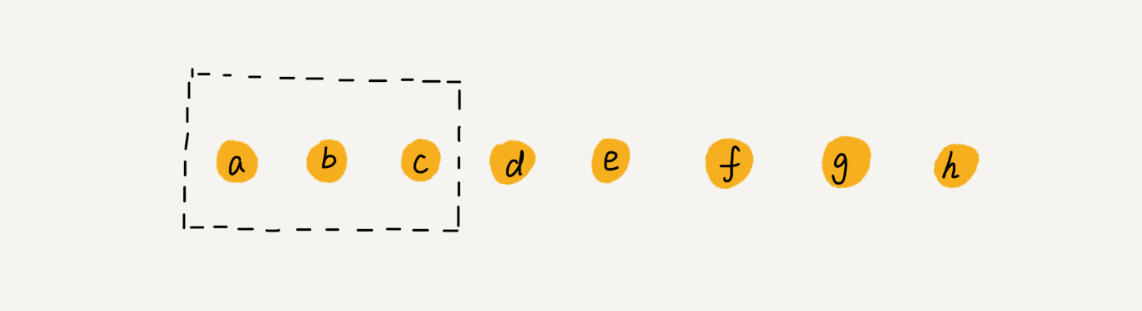
这样就大大减少了每次删除元素所需的位移操作。
这种标记删除状态的思想,也是JVM GC垃圾回收机制的核心思想。
ArrayList
谈到数组,使用Java语言就必离不开ArrayList,ArrayList是Java语言为我们提供的通过数组实现的数据存储容器,使用容器的好处就在于它为开发者已经封装好了增、删、查等算法,并提供一些其它方便又常用的特性,例如动态扩容。
ArrayList的动态扩容
我们都知道数组在创建时,它的内存大小就固定了,例如下面这个arr数组的内存大小为3,当我们给第4个元素赋值并运行时时就会抛出ArrayIndexOutOfBoundsException.
int[] arr = new int[3];
arr[0] = 1;
arr[1] = 2;
arr[2] = 3;
arr[3] = 4; //运行时抛出异常
当你使用ArrayList时,就无此烦恼:
ArrayList list = new ArrayList(3);
list.add(1);
list.add(2);
list.add(3);
list.add(4); //可以正常添加
通过ArryList源码我们可以发现其原理,首先ArrayList为我们创建了一个大小为3的数组(以下代码为ArrayList源码):
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity]; //初始化一个我们传入大小为3的数组
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
其次在添加元素时,如果数组大小不够用,扩容一个新的1.5倍的数组,然后再将原数组copy到新数组中,最后将元素加入:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 这个方法会去调用扩容相关方法
elementData[size++] = e; // 最后加入元素
return true;
}
// 扩容核心方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //扩容1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity); //copy一个新的大小
}
使用数组,还是使用ArrayList?
乍一看,ArrayList相比数组要好用的多,我们无需关心数组的大小是否公用,也无需知道增删操作的算法复诊度是多少。
是的,大多数情况下我们使用ArrayList就能满足我们的需求;
但当你的要存储一组基本数据类型数据,且对性能要求较高时,可以优先考虑使用数组,ArrayList在存储基本数据类型数据时,需要进行装箱、拆箱操作,会有一定的性能损耗。
当数据大小已知,无删、插、扩容需求时,也可考虑使用数组。
JVM GC标记清除算法
前文提到JVM GC标记清除算法这里简单介绍下。
基本思想:标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段。
在标记阶段,首先通过根节点做搜索,标记所有从根节点开始的可达对象,未被标记的对象就是未被引用的垃圾对象,在清除阶段清除所有未被标记的对象。